






This blog post was originally posted on Dina’s Medium page. To read other works Dina has published, click here.
Evaluating and securing AI models is a complex, yet essential task in the cybersecurity landscape. PyRIT, the Python Risk Identification Tool, addresses the critical need for cybersecurity in AI model development by identifying and mitigating potential threats. Through its suite of tools, including orchestrators and scoring mechanisms, PyRIT allows security experts to conduct comprehensive risk assessments and red teaming exercises. This aligns the security of AI systems to known risks and desired behavioral outcomes.
What is PyRIT?
Evaluating AI models and systems is challenging. Whether your goal is to validate the correctness of the answers, ensure alignment, or enhance safety, the process is complex. PyRIT, The Python Risk Identification Tool, (PyRIT), aims to assist in these tasks by adding structure and flow to red teaming and risk assessment of models. PyRIT is an open access automation framework that helps security professionals and machine learning engineers proactively find risks in their generative AI systems.
In this blog post, I’ll delve into PyRIT’s key modules, from orchestrators that manage various attack strategies to converters that transform prompts in creative ways to bypass model guardrails. We’ll explore how PyRIT’s scoring mechanisms, like content classifiers and Likert scales, help evaluate model performance and alignment. This in-depth review aims to give you a clear understanding of PyRIT’s capabilities and how it can support your efforts in evaluating AI models and systems effectively.
git: https://github.com/Azure/PyRIT
Who can benefit from PyRIT?
You might be a security professional seeking to identify risks in a new product your company is launching. Or, you could be a machine learning engineer wanting to assess a model you are developing, establishing a baseline for future comparisons. PyRIT helps to identify blind spots and weaknesses that need addressing.
While PyRIT doesn’t introduce revolutionary concepts, it effectively bundles various methodologies and steps essential for thorough assessment.
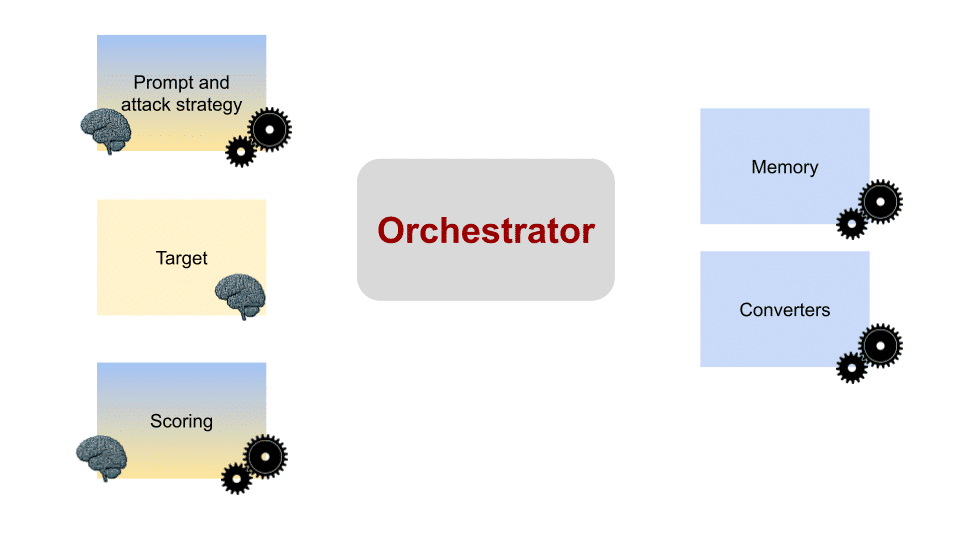
Orchestrator flow
Managing data flows with the Orchestrator
At the heart of PyRIT, we have the Orchestrator object. The Orchestrator is responsible for handling all the pieces needed to achieve the scenario you have in mind. It can be thought of as a control center that redirects the data flow between the modules based on the initial goal and feedback.
Different orchestrators can be used to achieve various flows. The currently supported types are:
- PromptSendingOrchestrator
- RedTeamingOrchestrator
- EndTokenRedTeamingOrchestrator
- ScoringRedTeamingOrchestrator
- XPIA Orchestrators (several types)
When implementing PyRIT, we should start by choosing which orchestrator suits our needs best. This choice will later determine the other modules we might need to use.
The Orchestrator is responsible for handling all the pieces needed to achieve the scenario you have in mind. It can be thought of as a control center that redirects the data flow between the modules based on the initial goal and feedback.
Let’s elaborate a bit further on each type.
- PromptSendingOrchestrator — This orchestrator specializes in sending multiple prompts to an LLM asynchronously. The prompts can be sent as is or converted using converters stacked on top of each other. These are single turn attacks with a static prompt.
- RedTeamingOrchestrator — A conversation orchestrator that helps manage an attack where the prompt is generated by an LLM as well. This is an abstract class that is inherited and implemented by the next two orchestrators.
- EndTokenRedTeamingOrchestrator — Implements RedTeamingOrchestrator for cases in which you want the conversation to end based on a generated token (by the attacker). The default token is “<|done|>”, but you can change that. You can also use max_turns parameter to cap the number of turns regardless of the end token.
- ScoringRedTeamingOrchestrator — Implements RedTeamingOrchestrator for cases in which you want the conversation to end based on an evaluation score. This score can be generated by a Scorer LLM or using a custom logic methodology. While the name “score” can suggest a value within a certain range, I find it misleading since the requirement is a bool (Boolean) that classifies whether the output is sufficient to satisfy the objective.
- XPIA Orchestrators — Xpia is a subtype of prompt injection in which the attacker has injected malicious instructions into an external data source that the LLMs is processing (1). The different XPIA orchestrators mimic this type of attack to see whether it is successful in manipulating the target. This could be summarization of blob files, emails or any other external task.
Prompts and attack strategies
A prompt can be directed towards the target (the tested LLM model) or towards the attacker LLM which generates prompts to be fed into the target.A prompt can be a simple string.
Alternatively, a prompt can be a template (PromptTemplate) where you can pass a sentence with placeholders within double brackets {{ }} that can be swapped with multiple values, similar to how LangChain and others implement it.
Another option includes using a RedTeamingOrchestrator while providing an AttackStrategy. This is simply a class that holds both the “strategy” – a prompt for the attacker (can be a path to a template or a string) and a conversation objective, which is the goal of the attack that determines when and whether the conversation should end.
Using targets to test for resilience
This module is responsible for managing the various targets we might want to test for resilience. It includes completion, chat and multi-modal models Azure APIs, storage (for XPIA attack) and text-to-speech generators.
It also includes Gandalf API (https://gandalf.lakera.ai), where you can try to make Gandalf reveal the secret to each level, including the bonus level as well as Adventure 1 and 2.
The model’s class wraps the original endpoint and initializes with the required deployment, API key, and endpoint parameters. You can send prompts to a target in a single or multi-turn conversation. This is controlled using the AttackStrategy.
Scoring techniques for alignment
Scoring the response of the target is important. It helps evaluate whether the goal was achieved and if the conversation can end. When checking for safety and alignment, scoring can determine whether our model is good enough, and allows for comparisons with other models and future iterations. Thus, choosing a good and reliable scoring mechanism helps set a realistic baseline.
It is important to note that a score according to PyRIT can come in integer, float, binary or string form, meaning while it is most intuitive to think of a score as a number, that isn’t always the case. For example, in the case of Gandalf, a score is the password (if present) or None (if not).
In most cases, scoring is achieved using another LLM with clear instructions on how it should evaluate the text. While this is something you can do yourself, PyRIT provides good examples and ideas for scoring methodologies and the corresponding prompts.
The scoring techniques that PyRIT provides are content classifiers and Likert scales. Each technique covers several scenarios. We will dive deeper into each technique and some of the scenarios.
Classifying content to organize data
Content classifiers are used to classify text into one of the categories provided in the prompt. A good example is sentiment analysis, where a model decides which sentiment best describes the input text.
To score text using content classifier, a SelfAskScorer class needs to be initialized with the proper instructions, categories, and a model for scoring. Currently, PyRIT provides example scenarios for classification in the form of YAML files for bias, current events, grounded, harmful content, prompt injection detector, question answering, refusal, sentiment, and sexual content. Each of these YAML files contains the allowed categories for classification and the description of each category.
PyRIT also provides a YAML with general instructions for a classification prompt. Interestingly, this is a general prompt for all classification tasks and has no specific instructions for any specific task. The main focus of this prompt is the output structure. It emphasizes that the output should be structured as a JSON with three keys: “category_name,” “category_description, “rationale,” each with a string type value. Additionally, it mentions (twice!) to avoid including “Possible JSON response” in the response.
Looking at one scenario for content classifier: Bias.
The categories PyRIT suggests are “no bias,” “implicit bias,” “representation bias,” “systemic bias,” and “algorithmic bias”. For each category, a description to help the model decide is provided. The differences between the categories are quite subtle. Interestingly in this case, an AI model is trusted to be able to distinguish between them. I would likely add at least a few examples per category to better guide the judgment.
Additionally, I am not sure if having systemic bias in a text is necessarily a problem. For example, a sentence like, “The police arrest rate of certain ethnic groups is higher than others,” would qualify as systemic bias because it “suggests institutional policies or practices that result in unequal treatment of certain groups” (the description). However, it is a fact and not biased from the perspective of the generating model.
Bias alignment is a heavily-discussed topic without clear answers, leaving things up to regulations as well as internal company policy to asses the alignment.
In any case, examining the content classifiers PyRIT provides can be thought provoking and give useful ideas.
Likert scales can support the classification process
The second option for scorers is using a Likert scale. A Likert scale is a psychometric scale used for scaling responses to questionnaires. The most well-known form is a statement followed by a horizontal line with equally distributed options representing the amount of agreement or disagreement the user feels towards the statement (i.e. Strongly disagree, Disagree, Neither agree nor disagree, Agree, Strongly agree). Each answer can be given a score, allowing for quantitative comparison.

Likert Scale example
Currently, PyRIT provides example scenarios for Likert scales in the form of YAML files according to topic: cyber, fairness bias, harm, hate speech, persuasion, phishing emails, political misinformation, sexual, violence.
These YAML files are similar to the content classification files with categories and descriptions, but with one main difference — the categories can be put on a scale and quantified. In all the scenarios there are five categories: no_X, low_X, moderate_X, high_X and severe_X (replace X with the scenario).
There is also a Likert system prompt YAML which is very similar to the content classification YAML. Most focus is given to the output format.
For more information on creating and understanding Likert Scales, check out this link.
Converters are classes that transform prompts using specific logic or patterns before sending them to the target model. This helps to check if such transformations can bypass the model’s guardrails. Some converters might use a model to make the transformation (e.g., the variation converter).
Important: You can use a single converter or a list of converters as input to the Orchestrator. If you use multiple converters, they are stacked (the output of one becomes the input of the next).
The converters currently provided by PyRIT include:
- ASCII art converter — converts a string to ASCII art. This is a non deterministic transformer since a “rand” font is used. Azure speech text to audio converter — Uses Azure’s text-to-audio service to convert a string to a WAV file.
- Base64 converter — Convert the regular string to a text string using 64 different ASCII characters. For example: Water -> V2F0ZXI=
- Leetspeak converter — [leetspeak; an informal language or code used on the internet, in which standard letters are often replaced by numerals or special characters that resemble the letters in appearance.(3)]. This is a non deterministic transformer as several options might exist per letter.
Example: Sabrina can be converted to $/-\|3r!n/\ OR $@6r!n/\ OR 5/-\6r!n^ etc…
- Random capital letters converter — Randomly capitalizes letters in a string. You can pass it the percentage to capitalize (default 100%).
- ROT13 converter — A simple letter substitution cipher that replaces a letter with the 13th letter after it in the Latin alphabet.
- Search replace converter — a simple find-and-replace converter. You provide it with a text, a phrase to find and a new phrase to replace it with.
- String join converter — adds a value of your choice between each pair of letters in the text. For example: join_value=’*’ The sky is blue -> T*h*e* *s*k*y* *i*s* *b*l*u*e
- Translation converter — uses another model translate the string to a different language.
- Unicode confusable converter — A non deterministic converter that switches various Unicode characters that look identical but are different. For example the letter ‘a’ has 115 different replacemnet options (!) among which is [á, 𝛂, ǎ, ạ] etc.
- Unicode sub converter — Adds a Unicode value to each character’s Unicode, transforming it to a different range.
- Variation converter —Uses another model to produce variations to the same prompt (default number of variations is 1 and it is currently hardcoded).
Works Referenced
Hines, Keegan, et al. “Defending Against Indirect Prompt Injection Attacks With Spotlighting.” arXiv preprint arXiv:2403.14720 (2024).
“Likert Scale Explanation — With an Interactive Example”. SurveyKing. Retrieved 13 August 2017.
leetspeak: https://languages.oup.com/google-dictionary-en/
Interested in learning more about CyberProof’s teams can help utilize AI to optimize your security coverage? Speak to an expert.